*Equal contribution †Corresponding author ‡Project leader
Reinforcement learning has emerged as a powerful tool for improving diffusion-based text-to-image models, but existing methods are largely limited to single-task optimization. Extending RL to multiple tasks is challenging: joint optimization suffers from cross-task interference and imbalance, while cascade RL is cumbersome and prone to catastrophic forgetting. We propose DiffusionOPD, a new multi-task training paradigm for diffusion models based on On-Policy Distillation (OPD). DiffusionOPD first trains task-specific teachers independently, then distills their capabilities into a unified student along the student's own rollout trajectories. This decouples single-task exploration from multi-task integration and avoids the optimization burden of solving all tasks jointly from scratch.
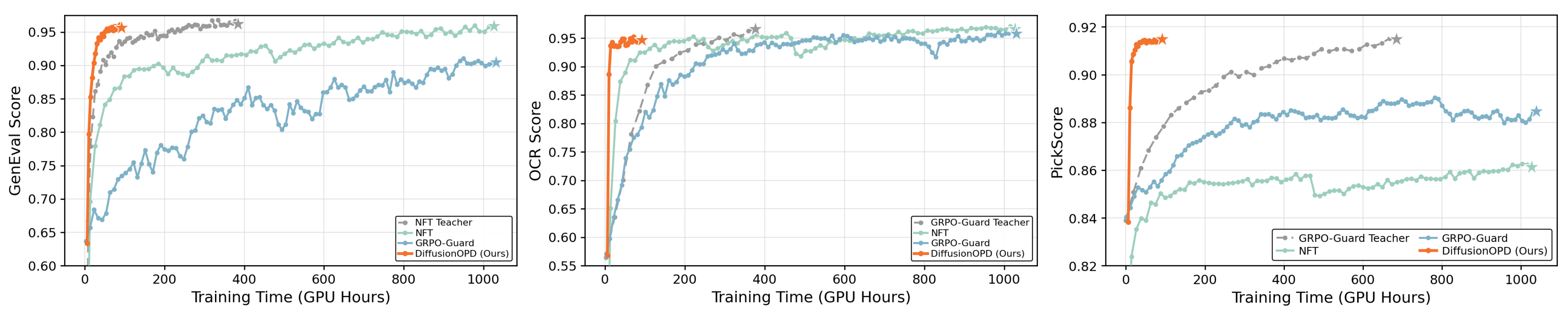
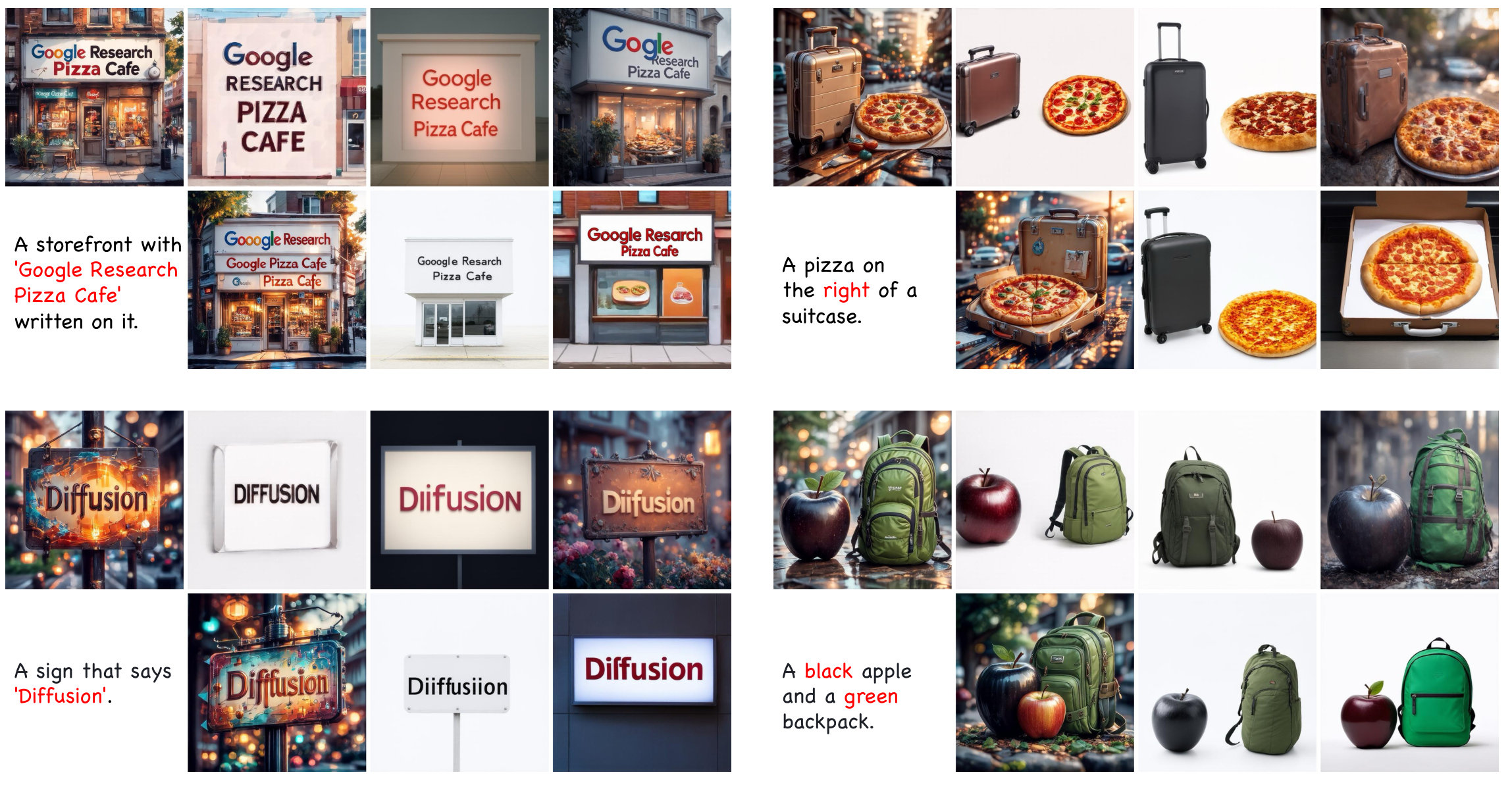
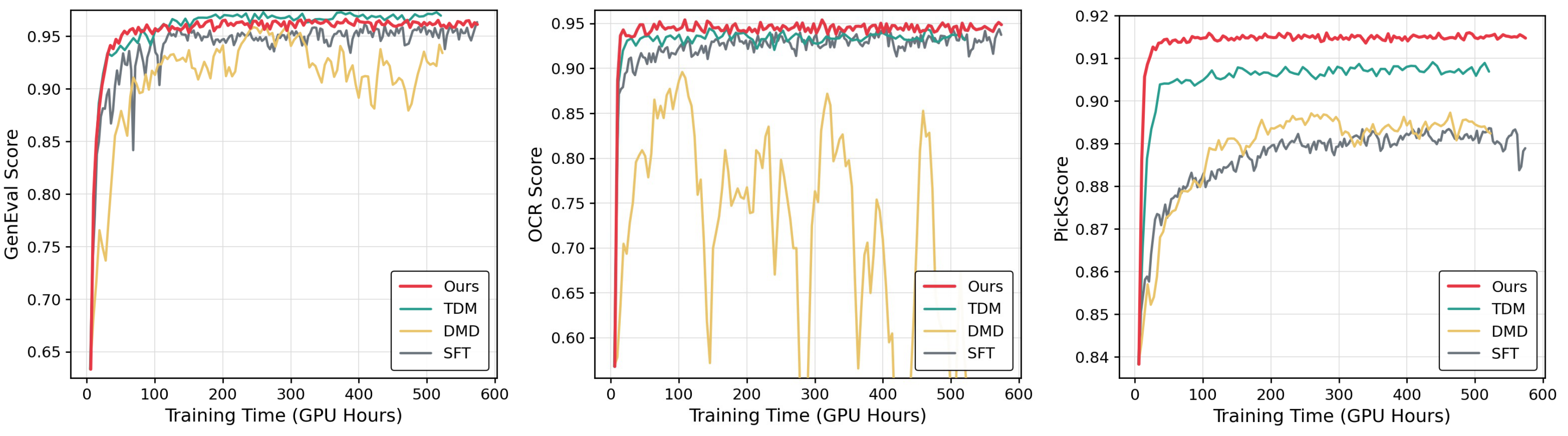
Theoretically, we lift the OPD framework from discrete tokens to continuous-state Markov processes, deriving a closed-form per-step KL objective that unifies both stochastic SDE and deterministic ODE refinement via mean-matching. We formally and empirically demonstrate that this analytic gradient provides lower variance and better generality compared to conventional PPO-style policy gradients. Extensive experiments show that DiffusionOPD consistently surpasses both multi-reward RL and cascade RL baselines in training efficiency and final performance, while achieving state-of-the-art results on all evaluated benchmarks.
A new paradigm where domain-specific teachers supervise a unified student along the student's own on-policy rollout trajectories, decoupling exploration from capability integration.
We derive a unified closed-form per-step reverse-KL objective that covers both stochastic SDE and deterministic ODE samplers — enabling lower-variance optimization than PPO-style gradients.
Consistent gains over prior baselines in both training efficiency and final performance, achieving SOTA on aesthetics, OCR, and GenEval simultaneously.
On-Policy Distillation (OPD), originally proposed for autoregressive language models, lets the student generate a full trajectory from its own policy and trains it to match the teacher on the prefixes it visits. We generalize this idea to any discrete-time Markov chain in which the student and teacher share the same state space and transition-kernel structure:
$$\mathcal{L}_{\text{OPD}}(\theta) \;=\; \mathbb{E}_{x_{0:N}\sim p_{S}}\!\left[\sum_{j=0}^{N-1}\;\mathrm{KL}\!\left(p_S(\cdot\mid x_{t_j})\,\big\|\,p_T(\cdot\mid x_{t_j})\right)\right].$$
For a flow-matching model with reverse-time SDE discretization (Euler–Maruyama), each denoising step induces a Gaussian one-step kernel $\;p_{S}(x_{t_{j+1}}\!\mid\!x_{t_j})=\mathcal{N}(\mu_S(x_{t_j}),\bar\sigma_j^2 \mathbf{I})\;$ and similarly for the teacher. Crucially, the per-step covariance $\bar\sigma_j^2\mathbf{I}$ depends only on the scheduler, so it is identical for student and teacher. The reverse KL therefore admits a closed form:
$$\mathrm{KL}\!\left(p_S\,\|\,p_T\right) \;=\; \frac{\lVert\mu_S(x_{t_j};\theta)-\mu_T(x_{t_j})\rVert_2^{\,2}}{2\,\bar\sigma_j^{\,2}}.$$
Plugging this into the OPD objective gives the diffusion-domain DiffusionOPD loss — an analytic, per-step mean-matching objective optimized by direct backpropagation:
$$\mathcal{L}^{\text{diffusion}}_{\text{OPD}}(\theta) \;=\; \mathbb{E}_{x_{0:N}\sim p_{S,\theta}}\!\left[\sum_{j=0}^{N-1}\frac{\lVert\mu_S(x_{t_j};\theta)-\mu_T(x_{t_j})\rVert_2^{\,2}}{2\,\bar\sigma_j^{\,2}}\right].$$
In the deterministic ODE regime, the student and teacher each induce a unique next-state target $\mu_S(x_{t_j};\theta)$ and $\mu_T(x_{t_j})$, so distribution matching collapses to pointwise transition matching — a clean squared-$L_2$ loss:
$$\mathcal{L}^{\text{diffusion-ODE}}_{\text{OPD}}(\theta) \;=\; \mathbb{E}_{x_{0:N}\sim p_{S,\theta}}\!\left[\sum_{j=0}^{N-1}\frac{1}{2}\lVert\mu_S(x_{t_j};\theta)-\mu_T(x_{t_j})\rVert_2^{\,2}\right].$$
The closed-form KL and the deterministic $L_2$ loss are two faces of the same training principle, providing a unified view of on-policy distillation across SDE and ODE samplers.
A natural alternative is to treat the teacher as a process reward model and optimize a PPO-style surrogate with the per-step KL as a dense reward. Under gradient accumulation, the importance ratio $\rho_j(\theta)=1$ and the PPO gradient decomposes as
$$\nabla_\theta\!\left(\rho_j(\theta)\,\Delta_j(\theta)\right) \;=\; \underbrace{\nabla_\theta\Delta_j(\theta)}_{\text{pathwise term}} \;+\; \underbrace{\Delta_j(\theta)\,\nabla_\theta\log\pi_\theta(a_j\mid x_{t_j})}_{\text{score-function term}}.$$
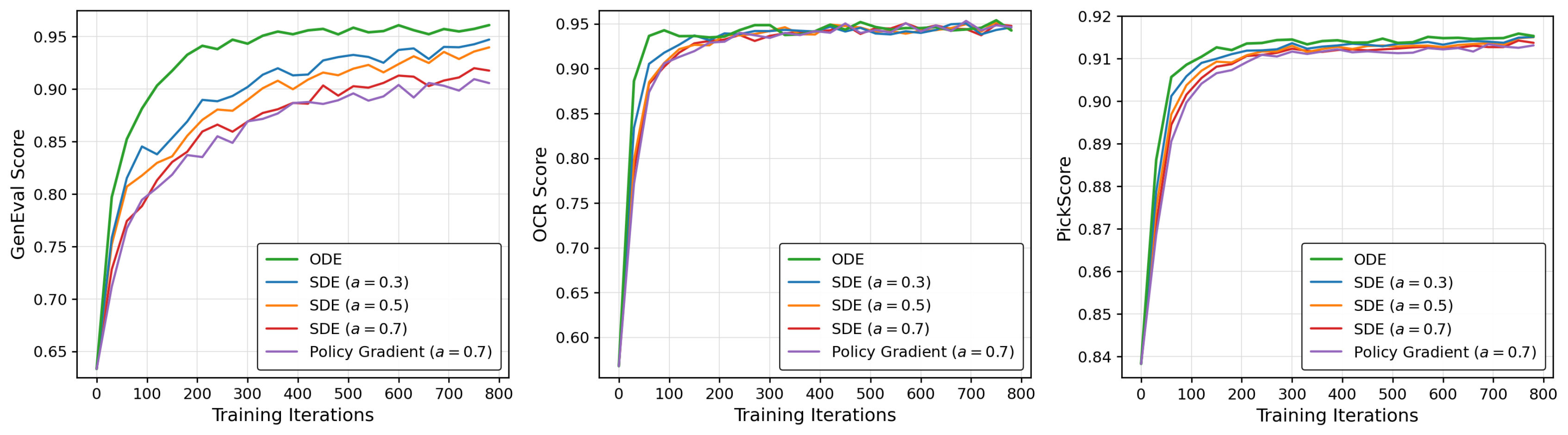
The score-function term is unbiased in expectation, but for a Gaussian transition $a_j=\mu_S(x_{t_j};\theta)+\bar\sigma_j\,\epsilon_j$ it equals $\frac{\epsilon_j}{\bar\sigma_j}\cdot\nabla_\theta\mu_S$, injecting noise proportional to $\epsilon_j$. In contrast, the closed-form KL is a deterministic function of $\mu_S$, so its pathwise gradient has strictly lower variance and remains valid under both SDE and ODE samplers.
Decompose the multi-task problem into $M$ individual tasks and train a specialized teacher for each reward using off-the-shelf diffusion RL (e.g., DiffusionNFT for GenEval, GRPO-Guard for OCR and Aesthetics). Each teacher can fully exploit its own reward without inter-task interference.
Initialize the student from the pretrained policy. In a round-robin manner, sample prompts per task, roll out the current student to obtain an on-policy trajectory, and supervise it with the corresponding teacher via Eq. (11) or Eq. (12). Losses are accumulated across all tasks and a single optimizer step is taken per round — yielding stable multi-task updates.
DiffusionOPD attains the best Average score (0.929), surpassing Multi-Task RL and Cascade RL baselines with a competitive wall-clock budget. Gray columns mark in-domain rewards used during teacher training.
| Model | Wall-clock (hours) |
Rule-Based | Model-Based | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GenEval | OCR | PickScore | ClipScore | HPSv2.1 | Aesthetic | ImgRwd | UniRwd | |||
| SD-XL‡ | — | 0.55 | 0.14 | 22.42 | 0.287 | 0.280 | 5.60 | 0.76 | 2.93 | 0.390 |
| SD3.5-L‡ | — | 0.71 | 0.68 | 22.91 | 0.289 | 0.288 | 5.50 | 0.96 | 3.25 | 0.601 |
| FLUX.1-Dev | — | 0.66 | 0.59 | 22.84 | 0.295 | 0.274 | 5.71 | 0.96 | 3.27 | 0.599 |
| SD3.5-M (w/o CFG) | — | 0.24 | 0.12 | 20.51 | 0.237 | 0.204 | 5.13 | -0.58 | 2.02 | 0.000 |
| SD3.5-M + CFG | — | 0.63 | 0.59 | 22.34 | 0.285 | 0.279 | 5.36 | 0.85 | 3.03 | 0.484 |
| GenEval Teacher | 46.92 | 0.96 | 0.40 | 22.04 | 0.274 | 0.248 | 5.24 | 0.59 | 2.97 | 0.473 |
| OCR Teacher | 33.17 | 0.65 | 0.93 | 22.27 | 0.290 | 0.272 | 5.26 | 0.90 | 3.09 | 0.550 |
| Aes Teacher | 85.75 | 0.49 | 0.59 | 24.02 | 0.295 | 0.346 | 6.22 | 1.498 | 3.48 | 0.698 |
| Multi-Task GRPO-Guard | 129.86 | 0.89 | 0.94 | 23.12 | 0.296 | 0.307 | 5.61 | 1.31 | 3.33 | 0.763 |
| Multi-Task NFT | 128.42 | 0.95 | 0.96 | 22.59 | 0.288 | 0.282 | 5.41 | 1.08 | 3.23 | 0.715 |
| Cascade NFT | 148.49* | 0.94 | 0.91 | 23.80 | 0.293 | 0.331 | 6.01 | 1.49 | 3.49 | 0.851 |
| DiffusionOPD (Ours) | 85.75 + 11.26† | 0.96 | 0.94 | 23.99 | 0.297 | 0.342 | 6.15 | 1.50 | 3.50 | 0.929 |
Gray-shaded metrics are in-domain rewards; bold marks the best result and underline the second best. ‡Evaluated at 1024×1024. *Approximated training time. †For DiffusionOPD, wall-clock = max teacher time + OPD training time.

If you find DiffusionOPD useful, please consider citing:
@article{li2026diffusionopd,
title = {DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models},
author = {Li, Quanhao and Yu, Junqiu and Jiang, Kaixun and Wei, Yujie and
Xing, Zhen and Li, Pandeng and Chu, Ruihang and Zhang, Shiwei and
Liu, Yu and Wu, Zuxuan},
journal = {arXiv preprint arXiv:2605.15055},
year = {2026},
eprint = {2605.15055},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}